privat1: Evaluating Adversarial Perturbations for Image Privacy
A Research Perspective on Pixel-Level Obfuscation against Automated Surveillance

Abstract
The privat1 project explores pixel-level adversarial perturbations designed to defeat automated mass-surveillance and AI vision systems. By injecting calculated adversarial noise, privat1 forces classification models to confidently misidentify subjects while preserving the image's visual integrity for human observers.
The framework currently targets MobileNetV2 (trained on ImageNet)—the foundational recognition engine for countless commercial security cameras and object tracking pipelines, proving that ubiquitous surveillance infrastructure remains highly vulnerable to localized, mathematical obfuscation.
The privat1.py Implementation and Pipeline
The current iteration of the privat1.py engine employs a multi-stage orchestration pipeline designed to fundamentally disrupt the structural feature extraction processes used by modern convolutional neural networks (CNNs).
Rather than relying solely on simplistic noise addition, the pipeline executes a multi-tiered mathematical approach:
- Structural Chaos (Bounding Box Disruption): AI models frequently utilize Intersection Over Union (IOU) to anchor subjects. The pipeline applies a subtle Random Perspective Transform to warp the spatial anchors of the image, misaligning the classifier's expected feature map.
- ** Main Adversarial Attacks ( f.e. PGD / FGM):** The core attack for example uses Projected Gradient Descent (PGD).
- PGD (Projected Gradient Descent): A powerful iterative attack that takes multiple small steps along the loss gradient to find the optimal noise perturbation.
- FGM (Fast Gradient Method): A faster, single-step gradient manipulation ideal for rapid batch processing.
- CW (Carlini-Wagner): A highly optimized L2-based attack designed to achieve extremely high-confidence misclassifications with minimal visual distortion.
- APA (Adversarial Patch Attack): Generates localized patches to force misclassification without altering the entire image.
- OPA (One-Pixel Attack): An extreme edge-case tactic that attempts to disrupt feature recognition by modifying a minimal set of pixels.
- STAA (Spatial Transformation Adversarial Attack): Uses small, imperceptible rotations and translations to break the model's spatial mapping.
- The Upscale-Delta Architecture: Traditional adversarial attacks are typically constrained to low-resolution inputs (e.g., 224x224). Applying these directly to high-resolution imagery dilutes their effectiveness.
privat1bridges this gap by downsampling the image, calculating the adversarial delta, and then intelligently upscaling and compositing that delta back onto the high-resolution source. This ensures the adversarial patterns remain mathematically potent without degrading the base image's sharpness. - Distractor Embedding & LSB Steganography: To further dilute the attention maps of the classifier, the engine blends distractor patches from a diverse dataset. Additionally, optional modules like
steg.pyutilize Least Significant Bit (LSB) steganography and fake metadata injection to create structural confusion on a binary level, thwarting deep-inspection forensics.
The Multi-Attack Arsenal
privat1 does not rely on a single method of attack. It utilizes a modular, multi-tiered mathematical pipeline capable of executing—and sometimes combining—various adversarial tactics depending on the target's sensitivity.
This modularity makes this pipeline adaptable to different machine learning models and architectures and also so powerfull. here is a snipped of how it might work out:
if not args.no_distort:
image = apply_pixelation(image, pixel_size=args.pixel_size)
image = apply_pixel_shift(image, shift_amount=args.shift)
image = apply_pixel_pattern_mask(image, opacity=args.mask_opacity)
image = apply_random_perspective_transform(image)
image = cv2.GaussianBlur(image, (3, 3), 0)
#Adversarial Attacks
if not args.no_adv:
attack_list = [a.strip().lower() for a in args.attacks.split(',')]
for attack_name in attack_list:
eps_to_use = args.eps
if attack_name == "fgm":
eps_to_use = args.eps * 0.8
image = apply_adversarial_step(
image,
attack_type=attack_name,
eps=eps_to_use,
iters=40,
target_label=args.target,
alpha=args.alpha
)
# Assets/Distractors
if args.assets:
image = embed_distractor_assets(image, Path(args.assets))
# Save and Strip Metadata
output_name = generate_random_name("jpg")
final_output = output_dir / output_name
# Stego/metadata removal
remove_metadata(image, final_output)The Upscale-Delta & Steganography Pipeline
Beyond the core attack generation, the pipeline applies structural chaos. Adversarial attacks are typically generated at low resolutions (e.g., 224x224). privat1 downsamples the image, generates the attack delta, and intelligently upscales and composites it back onto the high-resolution source.
Additionally, optional modules (steg.py) inject Least Significant Bit (LSB) steganography and fake metadata to create binary-level structural confusion.
[ Input Image (High-Res) ]
│
▼
┌───────────────────────────────────────────────┐
│ Stage 1: Structural Distortions │
│ ├─ Apply Pixelation │
│ ├─ Apply Pixel Shift │
│ ├─ Apply Pixel Pattern Mask │
│ ├─ Random Perspective Transform │
│ └─ Gaussian Blur Smoothing │
└───────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────┐
│ Stage 2: Adversarial Attacks │
│ ├─ Parse Attack List (e.g. PGD, FGM) │
│ ├─ Adjust Epsilon (e.g. scale for FGM) │
│ └─ Apply Adversarial Step (Iterative) │
└───────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────┐
│ Stage 3: Assets & Distractors │
│ └─ Embed Distractor Assets │
└───────────────────────────────────────────────┘
│
▼
┌───────────────────────────────────────────────┐
│ Stage 4: Output & Metadata Management │
│ ├─ Generate Random Output Filename │
│ └─ Steganography / Remove Original Metadata │
└───────────────────────────────────────────────┘
│
▼
[ Output: Protected Image (Adversarial) ]
│
▼
┌───────────────────────────────────────────────┐
│ Stage 5: Verification (Optional) │
│ └─ Run verify.py to ensure misclassification │
└───────────────────────────────────────────────┘Generational Improvements: Visual Fidelity vs. Efficacy
Early iterations of the algorithm successfully confused classifiers but often left behind heavy, visible artifacts. The attack was mathematically successful but visually obtrusive.
To achieve a consistent misclassification against the model, the image had to be severely degraded with obvious, high-frequency noise patterns:
To illustrate this, observe the early pipeline output below. To achieve a consistent misclassification against the model, the image had to be severely degraded with obvious, high-frequency noise patterns:

The modern pipeline utilizes upscale-delta blending and soft-screen distractor embedding, interweaving the adversarial noise seamlessly into the image's natural texture. It is highly aggressive against the neural network but remains almost imperceptible to the human eye.
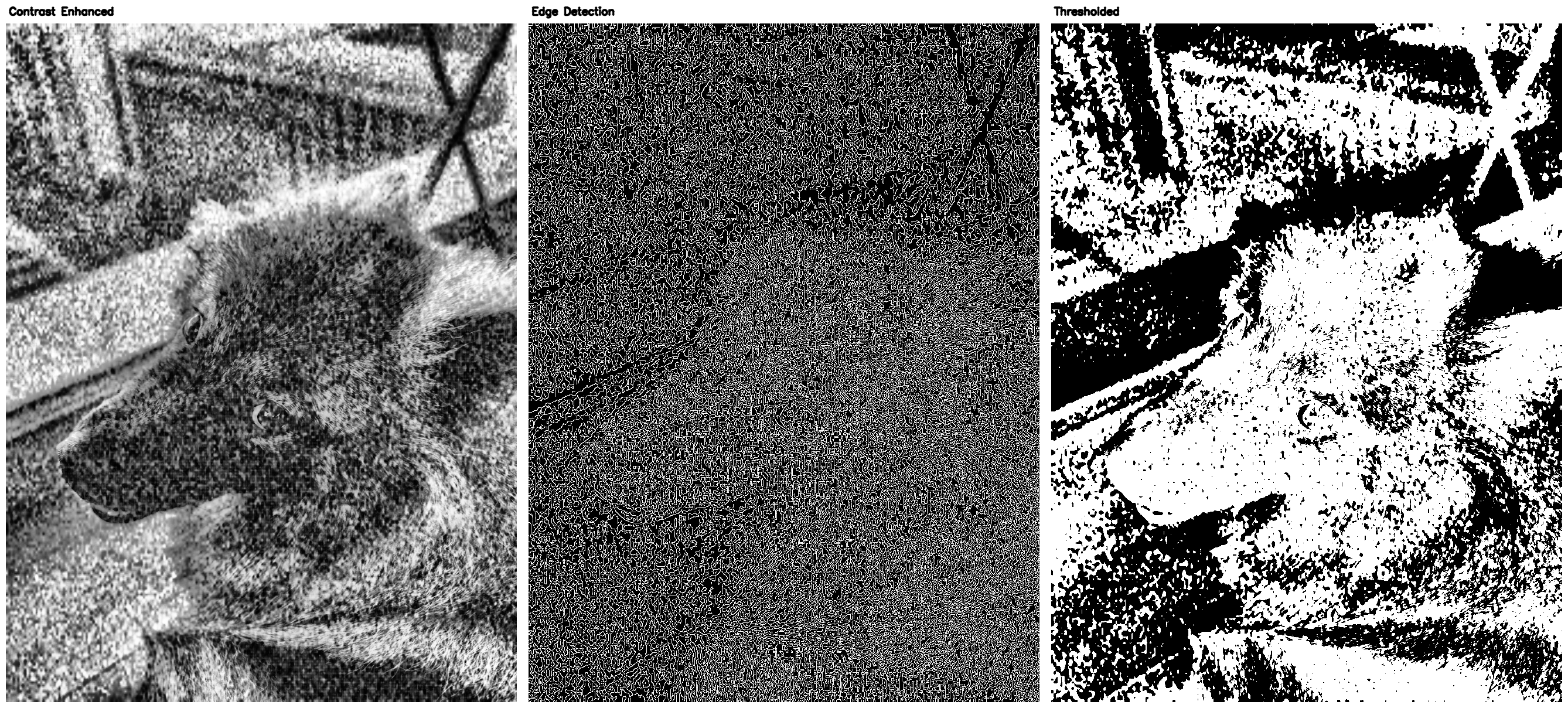
Forensic Analysis & Reversibility
A critical aspect of adversarial research is understanding how these perturbations manifest under forensic scrutiny. The enhance pipeline demonstrates how traditional forensic tools interact with our adversarial noise.
Edge Detection (Enhance2)
Standard edge detection is a common pre-processing step for many AI anomaly detectors. Because the adversarial noise fundamentally disrupts the local contrast gradients, the edge detector miserably fails to identify the subject's true outlines on a protected image, returning a chaotic mesh of broken structures.
Frequency Analysis (Enhance3)
Analyzing the Least Significant Bit (LSB) and Frequency Spectrum (FS) reveals the true nature of the attack. Even though adversarial data is heavily embedded into the image, the LSB pattern is randomized incredibly well, making it exceptionally difficult to detect the hidden data via standard steganographic detection methods. While the Frequency Spectrum gives hints to a trained eye that the image has been edited, the sheer randomness prevents simple reconstruction or noise filtering.

Empirical Results and Output Analysis
To validate the current pipeline, we executed a batch verification process on a set of protected images (the protected67 dataset) against the MobileNetV2 classifier. The verification script (verify.py) scans the processed images to ensure the targeted "forbidden" object is pushed down to an insignificant confidence level.
🔍 Summary (Sorted by Confidence):
INFO: ✅ dfafedcb9d84c6a0.jpg | lawn mower (20.1012)
INFO: ✅ 2abed15d7a754f0b.jpg | tow truck (19.8522)
INFO: ✅ 732dbf3fdeb7acbf.jpg | lawn mower (15.4166)
INFO: ✅ 3c0fdafac30cf9cf.jpg | lawn mower (15.4019)
INFO: ✅ 9e024bee01d50155.jpg | lawn mower (13.6923)
INFO: ❌ 59639fd9de6c7cab.jpg | schipperke (8.6995) | FORBIDDEN: keeshond at #8
INFO: ❌ 320c9ee5ddc550bc.jpg | schipperke (8.2832) | FORBIDDEN: keeshond at #9
INFO: ✅ 05d0aaf37244bc44.jpg | schipperke (8.1432)
INFO: ✅ ceb1cf048092e5c3.jpg | schipperke (7.3967)
INFO: ❌ a76aeeec5c7c0125.jpg | schipperke (7.3930) | FORBIDDEN: keeshond at #4Result Comparison
Let's examine how the classifier reacts to the adversarial noise across different samples:
Total Obfuscation:
In cases like dfafedcb9d84c6a0.jpg, the adversarial noise overwhelmingly dominates the classifier's attention map.
- Result:
INFO: ✅ dfafedcb9d84c6a0.jpg | lawn mower (20.1012) - The system registers a "lawn mower" with a massive confidence score of 20.1012. The original subject is completely masked.

Targeted Class Shifting: In other instances, the attack successfully shifts the classification to a closely related but distinctly different class.
- Result:
INFO: ✅ 05d0aaf37244bc44.jpg | schipperke (8.1432)

The Threshold of Perception:
Perhaps the most interesting result is found in 320c9ee5ddc550bc.jpg.
- Result:
INFO: ❌ 320c9ee5ddc550bc.jpg | schipperke (8.2832) | FORBIDDEN: keeshond at #9
While technically flagged as a "failure" by our strict validation script (because the forbidden class "keeshond" still appeared in the top 10), it is functionally a massive success. The primary classification has been hijacked by "schipperke", and the forbidden object has been buried down at rank #9 with a negligible confidence score.
What makes this specific example remarkable is the visual quality. The attack on 320c9ee5ddc550bc.jpg is barely visible to the human eye. The structural integrity and image fidelity are almost perfectly preserved, yet the adversarial noise is still potent enough to severely disrupt the image recognition algorithm, rendering the surveillance system ineffective.

Conclusion
By refining the pipeline to focus on intelligent upscaling, structural manipulation, and advanced gradient attacks (PGD/FGM/CW), privat1 demonstrates that privacy preservation against automated vision systems does not require the destruction of visual fidelity.